Architektur
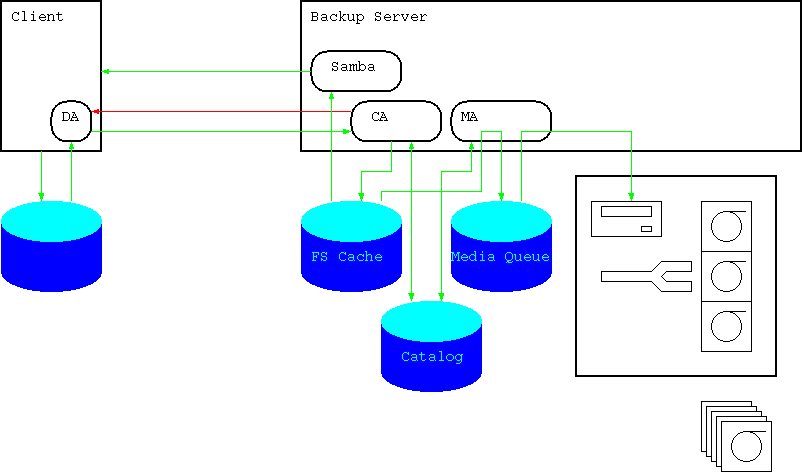
Das System besteht aus mehreren "Agents", die jeweils bestimmte Aufgaben haben. Die Abbildung zeigt einen Client (d.h., ein System, von dem Backups erstellt werden sollen) und einen Backup-Server, der die Backups verwaltet.
Collection Agent
Die Zentrale Komponente bildet der "Collection Agent", der in regelmäßigen Abständen (typischerweise täglich), Kontakt zu den Clients aufnimmt, den aktuellen Filebestand festellt, neue bzw. geänderte Files vom Client anfordert und im FS Cache sowie im Catalog speichert.
Der FS Cache hat die von rsync-snapshot bekannte Struktur:
- Ein Directory für jeden Zeitpunkt, an dem ein Backup begonnen wurde.
- Darunter ein Directory für jeden Client
- Darunter die gesamte Directorystruktur des Clients. Files haben die selben Metadaten (insbesondere Owner und Permissions) wie das File am Client), Files, die sich seit dem letzten Backup nicht geändert haben, sind Hardlinks auf das bestehende File.
Da jeder Subtree des FS Cache eine vollständige Kopie des entsprechenden Subtrees am Client ist, kann der FS Cache einfach über Samba oder ein anderes Netzwerk-Filesystem read-only export werden. Restores erfolgen einfach durch Kopieren der Files auf den Client.
Der Catalog enthält die Metadaten aller Files in einer relationalen Datenbank. Das dient einerseits der schnelleren Suche, andererseits dazu, Informationen über bereits auf Band ausgelagerte Dateien zu halten, die nicht mehr im FS Cache vorhanden sind.
Disk Agent
Der Disk Agent muss auf jedem Client installiert werden. Er dient dazu, Informationen über das lokale Filesystem des Clients an den Collection Agent zu übertragen. Im wesentlichen sind das:
- ein rekursives Listing eines Directories samt Metadaten
- Metadaten und Inhalt eines bestimmten Files
Der Disk-Agent kann konfiguriert werden, dass er bestimmte Directories, von denen kein Backup gewünscht ist (z.B. /proc und /sys auf Linux-Systemen, aber auch z.B. Directories mit Datenbankfiles) ausspart.
Im aktuellen Prototyp wird der DA über SSH gestartet, die Authentifikation erfolgt über Public-Keys. Sollte sich das als zu langsam erweisen, kann Agent auch über eine "nackte" TCP-Verbindung kommunizieren, die dafür notwendige Authentifikation ist aber im aktuellen Prototyp noch nicht implementiert.
Directorylistings und Filedaten werden über unterschiedliche Verbindungen übertragen, was effektives Streaming erleichtert.
Der Disk-Agent übersetzt systemspezifische Daten in ein "allgemeines" Format. Z.B. werden Filenamen vom lokalen Encoding nach UTF-8 übersetzt, und ACLs werden im POSIX-Textformat dargestellt.
Es wäre möglich, statt eines Disk-Agents, der auf ein Filesystem zugreift, einen zu implementieren, der beliebige andere Daten (Datenbanken, etc.) exportiert. Z.B. könnte ein Disk-Agent für Online-Backups einer Oracle-Datenbank folgendes Interface implementieren (bitte das als Beispiel zu verstehen, bei Oracle würde man wahrscheinlich eher RMAN verwenden):
- Ein Directory pro Tablespace mit einem Subdirectory pro Datafile und je einem Start/Ende-Markerfile.
- Durch Zugriff auf das Start/Ende-Markerfile wird der jeweilige Tablespace in den Backup-Modus bzw. wieder aktiv gesetzt.
- Jedes Datafile wird durch ein Directory von Files repräsentiert, die Teile des Datafiles abbilden. Für jeden Teil wird ein eigenes Last-Modified-Datum verwaltet.
- Archive-Logs werden als je ein File dargestellt.
- Der Collector-Agent sieht nur eine einfache Directory-Struktur, die er einfach rekursiv durchgeht, wodurch er den Disk-Agent dazu veranlasst die jeweil richtigen Tablespaces in den Backup-Modus zu schalten. Nur Teile von Datenfiles, die sich geändert haben, müssen über das Netz übertragen und auf Band geschrieben werden.
In diesem Fall ist das einfache Restore über ein Netzwerkfilesystem natürlich nicht möglich.
Media Agent
Der Media Agent dient dazu, Files auf Bänder (oder andere Wechselmedien) auszulagern.
Er liest Daten über den aktuellen Stand aus dem Catalog, bestimmt anhand seines Regelwerks, welche Files auf welches Band geschrieben werden müssen, und führt das durch.
Aus Performance-Gründen werden Files nicht direkt aus dem FS Cache auf Band kopiert. Speziell bei vielen kleinen Files wäre so nicht sicherzustellen, dass die zum Streamen erforderliche Transferrate erreicht wird. Statt dessen werden in der Media Queue Files sinnvoller Größe (1GB dürfte bauchgefühlmäßig für LTO-3 angemessen sein) im Standard-PAX-Format erzeugt. Diese Files werden dann 1:1 auf Band kopiert. Wahrscheinlich ist es sinnvoll, für die Media Queue eine eigene Disk (bzw. ein RAID-1-Paar) zu reservieren.
Der Media Agent besteht aus zumindest zwei Prozessen mit unterschiedlichen Aufgaben. Wahrscheinlich ist es sinnvoll, ihn in zwei Programme zu splitten ("Archiving Agent" schreibt in die Media Queue, "Media Agent" kopiert von dort auf Wechselmedium).